DRIVE
Please watch the video if Youtube doesn't work with you.
Presentation
Abstract
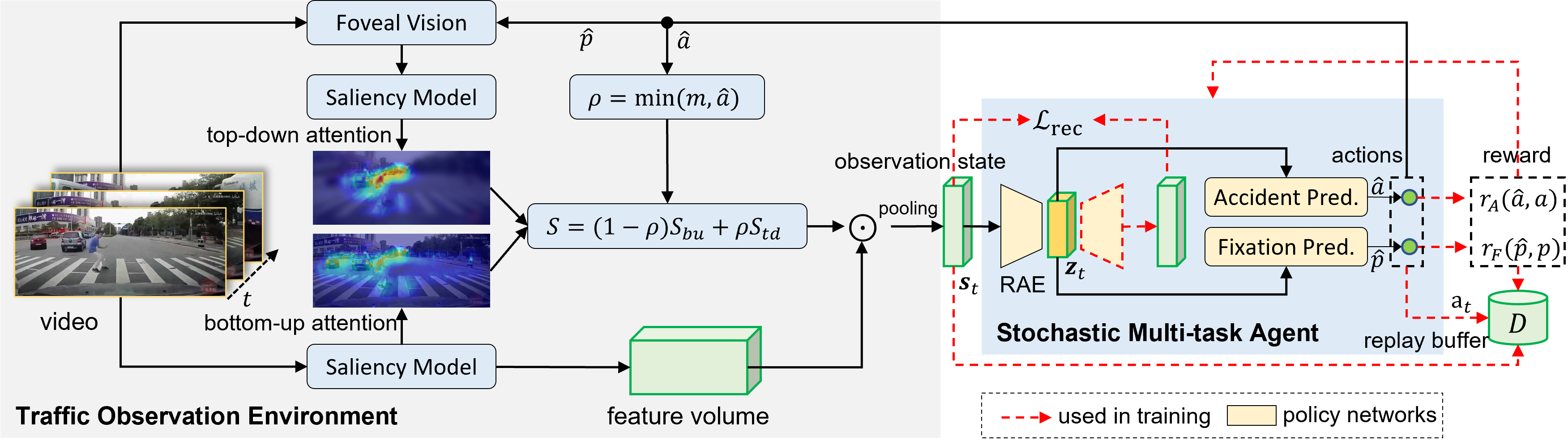
Traffic accident anticipation aims to accurately and promptly predict the occurrence of a future accident from dashcam videos, which is vital for a safety-guaranteed self-driving system. To encourage an early and accurate decision, existing approaches typically focus on capturing the cues of spatial and temporal context before a future accident occurs. However, their decision-making lacks visual explanation and ignores the dynamic interaction with the environment. In this paper, we propose Deep ReInforced accident anticipation with Visual Explanation, named DRIVE. The method simulates both the bottom-up and top-down visual attention mechanism in a dashcam observation environment so that the decision from the proposed stochastic multi-task agent can be visually explained by attentive regions. Moreover, the proposed dense anticipation reward and sparse fixation reward are effective in training the DRIVE model with our improved reinforcement learning algorithm. Experimental results show that the DRIVE model achieves state-of-the-art performance on multiple real-world traffic accident datasets.
CITATION
|
If you find our work helpful to your research, please cite: |
|
@inproceedings{DRIVE-BaoICCV2021, |