Research

Bayelemabaga
Bayelemabaga means “translator" in Bambara, the most widely spoken language in Mali. A collaboration between RIT, RobotsMali, Masakhane, the Malian National Education Center for Robotics and Artificial Intelligence, the Malian Ministry of Education, Higher Education and Scientific Research, linguists from AMALAN (Malian Academy of Languages), the University of Rochester Medical Center, and researchers from Orange Silicon Valley and Google, we aim to apply machine translation to Bambara and, ultimately, all the other national languages of Mali. All of these languages lack training resources (parallel texts). A major application area is translating public health information.
We are developing methods to collect and clean data and evaluate and train translation models using crowdsourcing. And are striving to become a national project in Mali as part of its initiative to use science and technology to advance its education and economic development. 80% of Malians do not master the official language of the country, French, and they therefore do not have access to information resources which could help them to contribute more to national development. The promotion of national languages is therefore an official objective of the Malian government and Bayɛlɛmabaga is a tool that can accelerate their widespread and effective use.
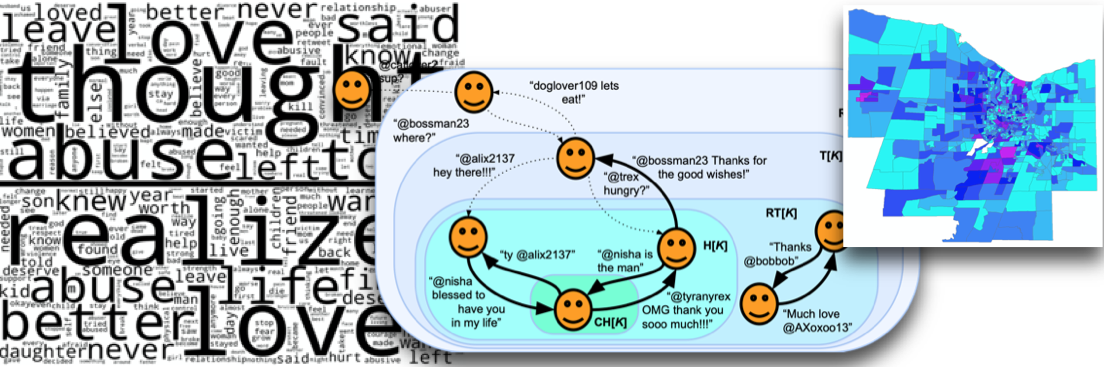
Predicting public health risks from first-person narratives
Health and well-being, particularly on a public scale, depends greatly on our actions, social and otherwise. Many people around the world spend substantial periods of their lives online. The amount of data online media provides about public behavior is thus vast and relatively easy to observe. Yet it is messy and unstructured and requires intelligence and expert knowledge to process. With partners from The University of Rochester Medical Center, The Children’s Institute, The Mental Health Association of Rochester/Monroe County, The Trevor Project, and industry, this project seeks to leverage machine learning and artificial intelligence to break this bottleneck and provide better and greater amounts of public health data to policy experts. We also seek to (1) better understand how communities---particularly underrepresented ones---provide support and resiliency for the health and well-being of their constituents, through fully experimental and observational studies (2) recruit and discover, in a statistically representative and ethically sensitive manner, members from hidden or underrepresented communities (such as men who have sex with men (MSM)).
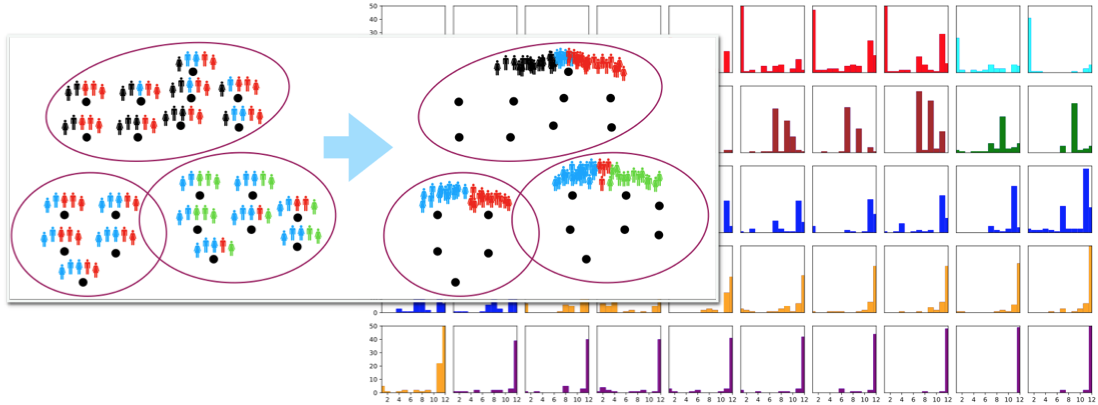
Diversity-preserving supervised learning
This project addresses basic problems that underlie our lab’s more application-driven activities. We study machine learning with humans-in-the-loop to detect socially relevant signals from social media and mobile platforms, particularly those that are subjective, i.e., where different stakeholders may interpret data in different ways. In particular, we are investigating a new model call population-level label distribution learning.